In our series of articles, we have discussed the relevance of the Six Sigma approach to software development. We have taken close looks at Define, Measure, Analyze, and Improve. Now is the time to examine the Control phase.
What is the purpose of adding ‘Control’ to our list of tasks? One major reason lies in the tendency of processes to lapse back into previous and undesirable behaviors. Our ‘Improve’ phase options may make for better software or better software development, but it is entirely possible that the new approach hasn’t taken root with our developers. By adding some reasonable measures to control regression to the past, we can help see to it that our new approach has a chance to become institutionalized in our organizations, be they large or small or somewhere in between. Additionally, control allows a continuous critique of the performance to some baseline, identifying areas for future improvements, making it possible to asymptotically approach perfection in the development processes.
Controls in Software Code
We can help ourselves by performing a set of behaviors designed to reduce or eliminate the anticipated relapse:
- Code reviews
- Code inspections
- Code walkthroughs
- Configuration Reviews
- Static analyzers
- Dynamic analyzers
- White-box testing
- Black-box testing
- Coding standards
- Practicing safe coding
Code reviews and code inspections are related concepts. Inspection will often have a pre-existing checklist, whereas code reviews need not be quite as formal. When discussing control, the actual mechanism of reviews/inspections is of less interest than the frequency of the activity, the critical eye toward the actual activity, and the potential milestones around which they occur. With the exception of very large subroutines/functions, we think it unlikely that the team will review the code in less than functional size; that is, the team reviews the code when the function is complete. Furthermore, the inspection team may set a threshold for the amount of change that can occur to a function before an inspection is scheduled—down to and including one or more changes.
Another version of code reviewing is the code walkthrough, with the primary difference being the leadership of the review by the developer or developers of the code. The other formats usually have team leaders who are quasi-independent of the developers. Walkthroughs can be used with specifications of any kind, test documents, models, and prototypes. The idea behind all of these methods of review is to invite other sets of eyes and viewpoints to critically review the software and/or documents for flaws. The defects of these approaches lie in the quality of the review itself and the experience and maturity of the participants. Much of the quality of the review hinges upon the amount of time in the preparing for the review. If a person shows up to the meeting and has not provide sufficient “up front” critique of the article, the expectation of accomplishing much should be lowered. We suggest, price of entry to the review being a marked up document. Those expected to attend, that can not show a marked up document, have failed to deliver and this should be noted.
Configuration management and reviews are equally important. There is abundant anecdotal evidence that suggests configuration management is a key success factor for software and embedded projects. Critiques of the configuration management plan and the details of the configuration through the development process can improve the quality of the system under development. If the project does not have configuration management, they have nothing. We know of at least one case where unknown hardware with unknown software was sent to a customer and, not surprisingly, did not function at the customer site.
The four sub-controls that are part of configuration management are:
- Configuration identification, wherein we give a name to the components with which we are working
- Configuration control, sometimes the most intense and expensive part of the process (and most lacking)
- Configuration status accounting, where we give ourselves regular reports about topics of interest in the system
- Configuration auditing, where we verify that our software function to requirements (functional configuration audit or FCA) and our documentation is correct (physical configuration audit or PCA)
Software configuration management systems are generally computer-controlled these days with well-known open source tools like Revision Control System (RCS), Concurrent Versions System (CVS), and subversion. Each of these systems can be persuaded to archive binary files such as those produced by office suites. Additionally, Microsoft Sharepoint provides a level of support for document management and many add-ons exist for it that support workflow and document management. Lastly, Parametric Technology Corporation provides a Product Development System (PDS) that serves the purpose of a change and configuration management system.
Static analyzers are tools the developer can use to automatically review the code for potential semantic flaws. One of the software archetypes for this kind of analysis is the tool lint. Lint provides a very detailed assessment of potential flaws, particularly with C code. Lint goes beyond the kind of syntax checking that any competent compiler will perform and adds analysis of items such as dereferencing, odd pointer usage, and bizarre casts. Gimpel Software has produced PC-Lint for twenty-five years and evolved the product over that time by adding more checks and allowing the tool to be used to make C a highly-typed language. Some pundits suggest that the use of the ‘#assertion’ pragma constitutes a form of static analysis also. Additionally, custom or proprietary tools can be developed that amount to DRC (Design Rule Checking) tools for the software. These tools evaluate the text of the software code against an organizations standard for structure and use of comments and module layout. This essentially provides some enforcement of an organization coding standards without a great deal of human resources.
Dynamic analyzers provide another dimension of code control, but with a tradeoff—they are difficult to use with embedded code. When not developing embedded code, the developer can use a dynamic analyzer to check the stack, key registers, interrupts, the heap, watch for memory leaks and corruption, and thread observation. Dynamic analyzers as a group tend to be much more intrusive with the code than the static analyzers. Embedded developers would most likely need to use hardware support tools such as logic analyzers and digital oscilloscopes.
White-box testing occurs when a tester, often the developer, works directly with the logic of the function to provide in-depth and very detailed testing. For example, the developer might provide a variety of modifications to the arguments of the function as well as modifying values of global variables (yes, eliminating global variables is a form of control!) to observe the effect on the function. In order to accomplish complete observation, the white-box tester must not only observe the values of the overt output of the function, but also take a look at the internal values of the function as well as changes to any other memory location used by the function. With an object-oriented modality, we would expect to see the developers make use of get and set functions as a means of controlling access to values within the function.
When we ask the testers to perform black-box testing, we are providing the means to avoid contamination of the testers by the developers. With black-box testing, we do not need to know the inner workings of the code. We provide a realistic set of stimuli to the software and observe for the expected output values all the while noting any unexpected or missing outputs. With embedded software, we can use combinatorial methods to enhance the efficiency of our test approach. The combinatorial technique uses pairwise, three-wise, and orthogonal arrays to provide a mechanically-predetermined list of inputs to the automated test code. The beauty of the combinatorial approach is that we can always estimate our coverage of the inputs and outputs as well as ensuring known levels of efficiency. The downside is that some of the approaches (for example, pairwise) will not observe input interactions except by accident.
Simulation is used early to develop the target for the software. We build models that will represent the software targets to be achieved. This will be continuously refined until it represents the final product. At which time the code will be generated for the product. The simulation code should fall under configuration management just like all the other code.
We use coding standards to help the developers to present a more uniform appearance, at a minimum, and to practice known good behaviors, at an optimum. Just by improving the appearance of the code, the comments, and the general layout, we make the code more amenable to the previously-mentioned code reviews. In short, we are improving the appearance to make life easier for the reviewers and to enhance the probability they will find what they need to find in the code. The coding standard can also specify the use of casts, pointers, array bounds checking and other control techniques to help eliminate stupid mistakes by the developers. On the administrative side, software development managers must enforce the use of standards. Sometimes, the static analyzers can help ensure that the developers are following the coding standard. One well-known coding standard for C is MISRA C, a software coding standard for the C programming language developed by MISRA (Motor Industry Software Reliability Association). Unfortunately, MISRA C is not available for free.
We practice safe coding when we follow certain practices that may or may not be part of our coding standard. One method for safe coding is to identify potential candidates for overflow or underflow issues and code checks to ensure that an exception is thrown before the catastrophe occurs or that some kind of correction is enabled. Another safe coding method is to require that all casts be explicit (another place where static analyzers can help us out). Safety critical projects may require that the developers use cleanroom techniques to develop the code: a combination of special diagrams, proof of correctness and statistically-based testing that tends toward zero defect software products. When available, functional languages such as F# and Scala will help to prevent side effects my eliminating the mutability of specific data structures (e.g., strings). Functional languages are generally unavailable for embedded development, but certainly deserve consideration in other venues. We once used pointers to achieve improved performance, but modern languages (and some old ones like FORTRAN!) are sufficiently optimized so that pointers should not be a necessity.
All of the methods we have discussed so far are truly controls on the software itself. However, the software development process itself can be enhanced with controls also.
Controls in Software Development
We can improve our process by adding the necessary controls to the stages of the process, for example:
- Lessons learned data base
- Failure mode and effects analysis on the process
- Process control plan
- Production software approval process
- Meaningful metrics and periodic presentations
- Defect density tracking
- Severity assessments
- Institutionalization of desired behaviors
- Regular training/indoctrination
- Design methodologies
- Model-based design
- Functional coding
We have already referred to the lessons learned data base in other articles and, in a sense, it is a kind of holy grail for all kinds of development as we try to answer the oftrepeated and plaintive question of upper management: “ why couldn’t you get it right the first time?” Another question often asked is “why did we make the same mistakes?” The idea behind the lessons learned data base is that we record our problems in some kind of structure format and record our solutions to the problems as well. Then, the tool can be used for learning, particularly if we:
- Require new employees to read through the data base
-
Have all members of the development and testing teams review it at least
quarterly - Require a special review of specific issues before and during a development
Over time we would expect to institutionalize this learning and then the lessons learned data base functions as a process control.
Over the years, we have the Failure Mode and Effects Analysis (FMEA) recommended for use on software designs or software code. We suspect that this would be a serious misuse of a tool that was never designed to operate on designs at the level of complexity of software. However, we see no reason why we cannot use the FMEA on the process itself (usually called a PFMEA). For each process step, we can analyze the input (cause), the output (effect), and the breakdown in performance (failure mode) and implement contingency plans or anticipatory actions to eliminate high risk failure modes. In the past, we have recommended the use of PFMEA on project plans since project managers usually do not have a convenient tool for the preparation of contingency plans.
The Process Control Plan is a tool used in the automotive, food, and pharmaceutical industries as a means for documenting the steps of the process, associated metrics and requirements, key process characteristics, and reaction plans.
Another automotive tool is the Production Part Approval Process (PPAP), which includes a minimum of eighteen documents that support a product release. We recommend the implementation of a software analog called the Production Software Approval Process (PSAP).
The PSAP would provide for collection of softwaresignificant documents.
For example, one approach might include:
- The original customer specification if one exists
- The software development plan
- Software test plans
- An operational concept description or concept document
- System/subsystem specifications
- Software requirements specifications
- Interface requirements specifications
- System/subsystem design descriptions
- Software design descriptions
- Interface design descriptions
- Database design descriptions
- Software test descriptions
- Software test report
- Software product specifications, which might include the executable software, the source files, and information to be used for support
- Software version descriptions for each variant of the software release as it evolves
- Firmware support manual for embedded software
The PSAP allows the software organization to bundle a complete package of information about the software product for internal review as well as potential customer submission and review.
The development team should use meaningful metrics and periodic presentations of metrics to assess their progress. One metric for a given software package (or by function) is defect density tracking, where we look at the ratio of defects to lines of code (or function points, feature points, or story points). We would expect and hope that the defect density of the product would decline over the duration of the project. An additional approach might include the use of the Rayleigh model. The illustration that follows shows the Rayleigh distribution (really a Weibull distribution with a shape factor of two):
Over the years , we have the Failure Mode and Effects Analysis (FMEA) recommended for use on software designs or software code . We suspect that this would be a serious misuse of a tool that was never designed to operate on designs at the level of complexity of software .
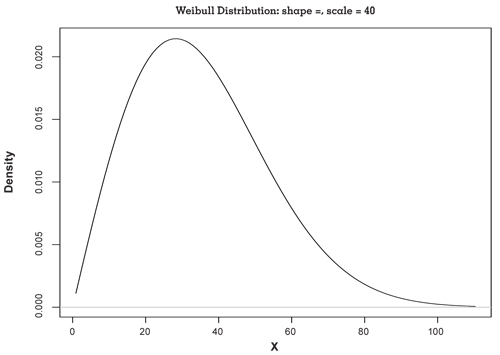
As we can see, the defect arrival rate against time is initially relatively low, but as we create more functions and more complex functions, we see a peak value for defects. As the development work begins to subside, the defect arrival rate abates and, ultimately, we have some statistical basis for making a release. Of course, diligence in reviews, inspections, testing, and other control activities strengthen the statistical argument.
We use severity assessments as part of a risk mitigation activity. The approach is straightforward: we assess the severity of each function by the amount of damage the function can do if it does not behave correctly.
The malfunctions include:
- Too much of a given behavior
- Too little l Static behavior (lockup)
- Periodic unexpected behavior
- Aperiodic (random) unexpected behavior
- No behavior (no startup)
In some cases, embedded software will be located in a safety critical application like an anti-locking braking system. Clearly, the undesirable behavior in a vehicle braking system would have a high severity. We might also assign high severities if the malfunction could put us out of business. Regardless a form of ranking the impact of the risk, whether catastrophic or a perception issue, is necessary to develop a course of action.
The institutionalization of desired behaviors is more than the lessons learned data base. Some behaviors meriting reinforcement include telling the truth when we discover a major software error, frequent reviews, even more frequent testing, and complete documentation. Over time, institutionalized behaviors should become part of the culture, but may need reinforcement as normal employment turnover occurs.
Regular training and indoctrination is a tool for clarifying management expectations with regard to software development. In our experience in both engineering areas and manufacturing plants, we have seen organizational knowledge degrade when not reinforced. Employee turnover will cause this decay to occur naturally. Indoctrination sounds somewhat negative, but what it really means is that we are spelling out the doctrine of how we expect our development, verification, and validation to occur. Regular training and indoctrination, over time, will lead to institutionalized behaviors followed by acculturation of the team. Otherwise, your organization is “hoping” that the desired behaviors and risk tolerance levels are magically maintained. Our experience suggests that the failure to use this simple and cost-effective control leads to a myriad of problems as the knowledge of our work forces naturally degrades through turnover and the lack of reinforcement leads to “extinction” of the desired behavior or application of the knowledge.
The software development team may select design methodologies that support better control of software concepts, design, coding, and verification. The use of known good code from libraries is a control in itself. In addition, the team and/or management may choose to use clean room development, the Rational Unified Process, structured programming, UML, simulation, and a host of other techniques to reduce the risk of bad software. We have seen some evidence that graphical techniques such as UML do increase the quality of the software, meaning we are not simply producing a set of pretty pictures to dazzle our customers. As development techniques evolve, we would expect to see more and more cases where the developer rarely leaves the design mode; that is, the developer will compile the design rather than compiling the code. Such is the case with some UML products and it has always been the case with the Telelogic software that supports ITU standards Z.100, Z.105, and Z.120. In fact, parts of UML are derived from the ITU standards.
Without control on the coding or the process, we would expect any improvements to degrade after implementation. The controls provide us with some measure of confidence that our improvement will remain until the next wave of improvements and, perhaps, even after that.
Final Comments About Six Sigma in Software
Our exploration of Six Sigma and software test and performance has taken us through the phases of define, measure, analyze, improve, and control (DMAIC). This simple algorithm makes it very easy to remember what to do when we discover or recognize a major issue with our software. Although we have discussed some items like project charters and Black Belts that may seem heavy-handed to some practitioners, any of these items may be tailored to fit the needs of the individual development and testing teams. The beauty of the approach lies in the simplicity of the basic algorithm, which ensures that we will never leave out a major step and, perhaps most importantly, we will define (scope) the problem before we dive in and assume we know what is going on with the software or the process.
Both of us have substantial experience in embedded development. The problems we see often require an understanding of the electrical, electronic, mechanical, and software behavior of the product. Frequently, problems are timing related and intermittent. These kinds of problems are nightmares to troubleshoot and the concept of defining what is and what is not the problem can be a big help in arriving at the cause of the observable mal-behavior.
About the Authors
Jon Quigley Jon M. Quigley PMP CTFL is a principal and founding member of Value Transformation, a product development training and cost improvement organization established in 2009, as well as being Electrical / Electronic Process Manager at Volvo Trucks North America. Jon has an Engineering Degree from the University of North Carolina at Charlotte, and two Master Degrees from City University of Seattle. Jon has nearly twenty-five years of product development experience, ranging from embedded hardware and software through verification and project management.
Kim Pries: Consultant principal, Director of Product Integrity and Reliability, Software Manager, Software engineer, author (books and magazine articles), DoD contractor and much more. 7 national certifications in production/inventory control and quality and 4 college degrees.