
Introduction
In 1987, the movie Platoon swept the Academy Awards with 8 distinct awards including Best Picture. Anyone that watched the movie Platoon recalls Charlie Sheen’s role as “Chris Taylor” – a privileged young man who decided to leave his university studies to enlist in the infantry division of the U.S. Army at the height of the Vietnam War. The idealism that led him to voluntarily enlist to fight in Vietnam quickly fades as he witnesses the brutal reality of war exasperated by internal conflict between two Sergeants in his own Platoon.
Staff Sergeant Barnes’ (Tom Berenger) and Sergeant Elias’ (Willem Dafoe) opposing beliefs on how to engage the Viet Cong soldiers in battle caused the Platoon to divide. Soldiers chose sides, communication broke down, and the enemy soldiers ultimately gained a competitive advantage over the Platoon in battle. The internal opposition between two key people in the Platoon led to a communication breakdown that contributed directly to the cold-blooded murder of Sergeant Elias at the hands of Barnes. And eventually it led to the death of Sergeant Barnes at the hands of his subordinate solider, Taylor.
As the tension and suspicion mounted within the Platoon about who really killed Elias, Chris Taylor and others confronted Barnes. They suspected that Barnes murdered Elias himself on a day patrol. Nobody could prove this to be true, but the soldiers were convinced that Barnes was guilty. If you watched Platoon, you recall Taylor attempting to rally his fellow soldiers to then ‘take out’ Staff Sergeant Barnes in an “eye for an eye” form of military justice. Barnes overhears the conversation that Taylor is having with the other soldiers and makes his appearance known to the men by walking into the tent.
As Barnes approaches the soldiers, he expresses his opinion on the conflict and ideology that Staff Sergeant Elias holds for the Vietnam War. In that heated discussion, Barnes speaks with authority:
“When the machine breaks down, we break down — and I won’t let that happen.”
– Sergeant Barnes, Platoon
Unfortunately, the machine did break down – in a very bad way. And it broke down with cold blooded murder. Barnes killed Elias, which ultimately led to Taylor killing Barnes. Meanwhile, most of the Platoon died in combat at the hands of the Viet Cong. It was a total loss. You might be asking yourself: how does Value Stream Integration and Software Quality Assurance even remotely relate to the most controversial War in American history? For the most part, it doesn’t relate – except for one critical component: the communication flow between machines. In Platoon, the two machines were Staff Sergeant Barnes and Sergeant Elias. In our world of Software Delivery and Quality Assurance, machine break downs include systems not integrating, people not communicating, and the resultant defects that occur in the application under test.
For most reading this article, we’ll never face the extremity of life-or-death at our place of work, but we do face communication breakdowns that can negatively impact our business models almost overnight.
Fast forward to 2018. Fluid communication is still the lifeblood throughout high-performing software defined enterprises. Whether it be communication between people, alignment of processes, or integration of working artifacts between Agile Planning systems – the concept of Value Stream Integration (VSI) is a hot topic amongst CIOs. What your CIO may not realize is that the cascading affect of Value Stream Integration is often seen by Software Quality Assurance Managers. When the QA Leader is not communicating properly with the Development Leader, Scrum Master, or Product Owner due to a “machine breakdown” – the team breaks down. The vice versa applies: when communication in the form of work products, status updates, and in-process changes are not flowing fluidly from Development to QA – the machine breakdowns in the sense that test suites become brittle and ineffective.
Improving Software Quality Assurance with Value Stream Integration is a matter of ensuring that communication never stops flowing between people, process, and technology. 7 Reasons Why Value Stream Integration Improves Software Quality Assurance showcases real-world experiences as to why embracing value stream integration will lead to dramatic improvements in an organization’s quality assurance and test management function. In this article, I will highlight how VSI can help your organization achieve:
- Higher Awareness of the QA Function to Improve Software Quality and Delivery Velocity
- Dramatic Improvements to your Defect Detection Effectiveness (DDE)
- More Effective Change Impact Analysis, Control, and Management
- Improved Test Coverage with Real-Time Feedback Loops
- “Shifting Left” to Reduce Costs and Improve Team Morale
- Elimination of the “Ping Pong Effect” – Developer and Tester Alignment
- Accelerated Buildouts of Global Testing Centers of Excellence
Why Embrace Value Stream Integration for Quality Assurance?
According to the Business Dictionary, a Value Stream is a sequence of activities required to design, produce, and provide a specific good or service, and along which information, materials, and worth flows. The fragmentation of value streams is what ultimately leads to inefficiencies and ‘machine breakdowns’ (defects) in your software delivery lifecycle. Expectations and demand couldn’t be higher on CIOs, Project Managers, DevOps Leaders, Scrum Masters, Product Owners, Developers, QA Analysts, QA Managers, and Testing Managers. Everyone is feeling the pressure – not just the CIO. The advent of the Agile-age of Software Delivery, coupled with the bar set by the “Big 4”: Amazon, Google, Facebook, and Apple have created a sense of inadequacy across the world when one looks at improving their SDLC quality and velocity.
Let’s face it: most organizations are inadequate if you compare yourself to the speed of software delivery seen by any of the Big 4. They have mastered the art of Agile, DevOps, Quality Assurance, and everything in-between. Their business models, from the very start, hinged on creating the most efficient value stream network. Their software-defined enterprises are now the blueprint for other organizations to model. The problem though is that many organizations don’t have a clean slate to build from, or don’t realize the importance of embracing value stream integration with their existing tools, people, and processes to improve both velocity of delivery and quality of software. Many companies are reactively ‘patch working’ their software systems, as opposed to focusing and fixing the root cause of their software quality issues – which I believe to be a lack of end-to-end value stream integration.
I’ve seen organizations struggle to orchestrate disparate tools, processes, and people – while trying to live up to “the new standard,” the new blueprint, only to fail as they try to scale a “pocket of success” within their company to other departments. Even with a greenfield to work from and an impressive budget for the best people, tools, and blueprints – organizations sometimes miss the mark by overlooking the fundamentals of value stream integration. And this is where the sense of inadequacy stems. The question often becomes: does an organization require a greenfield to create a world-class value stream like the Big 4, or can they tie their existing assets together to achieve an end-to-end value stream that improves software quality?
I believe that every job is unique and requires a specific set of tools to accomplish the best outcome. In the world of software, these are known as “best-of-breed tools.” Have you heard the saying that you never show up to a gun fight with a knife? Well, when analyzing code for cross-scripting errors, you’re not going to throw a manual testing add-on tool at the job – but rather a more specialized best-of-breed tool that provides deeper vulnerability analysis and automated code scans, right? A tool designed specifically for the job-at-hand. Sure, you could attempt to use a generalized ‘one size fits all’ tool to carry out a very specific task – but you add risk to your value stream and often slow down delivery at the same time.
As the world of software delivery evolves and DevOps takes root in enterprises both large and small, we will continue to see a proliferation of specialized tools appear along enterprise value streams. From left to right, we’ll see advancements in requirements management tools, enhanced build and source code management repositories, better IDEs, CI and CD coming together, more prolific programming frameworks, easier-to-use unit testing tools, model-based automation tools, better manual testing add-ons, and end-to-end platforms that attempt to tie-it-all-together. The one constant that remains with the introduction of each new tool into your value stream is that quality remains everyone’s responsibility.
If your QA team is using a model-based automation tool to design automated test scripts, but they aren’t ‘invited to the party’ until weeks before build is complete – or worse, do not have the visibility into the requirements, design, and build – you can expect deficiencies in the quality of the testing coverage. By integrating your value stream, from end-to-end, you’re ensuring that quality is at the forefront of everyone’s mind as software work products mature, evolve, and reach the end consumer.
Let’s look at the 7 Reasons Why Value Stream Integration Improves Software Quality Assurance:
1. |
Value Stream Integration surfaces the good, the bad, and the ugly as requirements are conceptualized, designed, and documented. QA is no longer an “afterthought” (test what we can when we can), it’s a fully integrated function of the SDLC. QA now has a seat at the “adult table” when organization’s embrace the concept of value stream integration end-to-end. |
Cuba Gooding Jr. said it best in Jerry McGuire when he told Jerry that he felt like he was 5 years late for the Prom at a promotional event. As a QA practitioner, have you ever felt 5 years late to the prom? I’m sure you have – I certainly have felt this way a few times in my career. The Solution Architects, Business Analysts, and Product Owners are meeting on a regular business to fully define the set of business requirements. They are working to ensure that requirements are clear, unambiguous, and fully documented. Whiteboard sessions are occurring, deep discussions are occurring, debates unfold, and real meetings of the minds are taking place. The entire team internalizes what needs to be accomplished for an Epic, Theme, Feature, or User Story.
The Business Analysts are busy capturing the discussions, conceptualizing the business needs, and documenting everything in the form of Functional Designs. Perhaps the Functional Designs aren’t formalized, but the BA is taking snap shots from their Smartphone of the brain dump that the Business Stakeholders are whiteboarding in the conference room as discussions unfold. I’ve even seen some BAs record the discussions with the business on their phone to later refer to it as they think through and document the workflow in Microsoft Visio.
Although we’d like to think that software development is mostly science – there are many soft (human) elements that go into a high-performing software development team. Methodology, process, and framework are important – but there is nothing more important, in my opinion, than a bunch of smart people sitting around in a room fleshing out the requirements together. In my career, I’ve had the privilege of working with the best-of-the-best in this manner. You’ll know it when you’re participating in a requirement gathering session like this – it’s almost as if the rest of the world fades away and everyone’s intellect is singularly focused on the task at hand. It’s exhilarating.
How does Value Stream Integration ensure that QA gets a seat at the adult table? Let me explain. Most of my career, I have seen companies use a variety of tools to help define requirements, manage projects, and run testing efforts. There are a few tools in the market that offer features that can help with a variety of these functions, but in my experience, everyone is working with a variety of tools. Take for instance JAMA (www.jamasoftware.com). Undoubtedly, a great tool to define, store, and review requirements with some awesome collaboration features. It also includes a slick test management capability – but what if another part of your organization involved in a cross-functional software modernization project has been using Micro Focus Quality Center, Zephyr, or perhaps even QA Symphony for Test Planning, Design, and Execution? As requirements are developed in Jama – your team doesn’t have line-of-sight iterative visibility as they unfold. Although your QA team might be invited to have a seat at the requirements definition table, they will not be able to get a head start on those high-level testing scenarios without the necessary upstream visibility. You’ve heard it before: “we have no more licenses,” or they might be able to provide you with access – but there is nothing more cumbersome than bouncing between two different tools.
With Value Stream Integration, facilitated by Tasktop Integration Hub, your organization can quickly & easily tie together Jama with best-of-breed Test Management tools on the market today. Doing so inherently provides your QA team with upstream visibility to witness the iterative creation of requirements. As those whiteboard images are attached to artifacts (requirements) in Jama, they are flowing like water into your tool-of-choice as a QA practitioner so that you can start drafting those high-level test scenarios. It’s a win-win: not only are you sitting at the table at the early inception of a project as a QA practitioner, but you’re plugged into the artifact creation value stream. As the work products are created upstream, they are flowing iteratively (as changes are made) into your tool-of-choice. If your team is using SharePoint to document requirements with attachments, you can also tie that into your downstream Test Management tool. The possibilities are endless, but the point is that QA must have unambiguous requirements to develop accurate and comprehensive test coverage. Ensuring that your team has line-of-sight visibility upstream as requirements are created will ensure that everyone understands what is coming down the pike. This, in turn, creates cross-functional understanding – resulting in higher quality test coverage.
2. |
Bridging ITSM with ADM, calculating Defect Detection Percentage (DDP) on-the-fly – It’s not just about Code Commit to Release Time, DDP helps organizations measure how effective their regression testing is at trapping bugs before release. Value Stream Integration bridges the gap between ADM and ITSM. |
According to the ISTQB Glossary of Terms Used in Software Testing, Defect Detection Percentage (DDP) is measured by the number of defects found by a test phase, divided by the number [of defects] found by that test phase and any ‘other means afterwards’. Other means afterwards, in the context of this article, relates to ‘incidents’ identified by end users consuming software. Those end users could be consumers of your software in the real-world, or internal stakeholders of your business performing operations within the software released. Either way you look at it, an ‘incident’, a ‘defect’, a ‘bug’, or an ‘issue’ really describes the same thing — an abnormality in how your software is operating in accordance to the requirement. In other words, there is a variance between how the software should operate versus how it is operating. Whether that is identified by the Software QA Team within the confines of the SDLC (the project), or identified after the software build is released into-the-wild, generally determines whether the abnormality is classified as a “Defect” or an “Incident” by most organizations.
The evolution of software delivery and the best practice trends were in part created by market leading tools such as HP (now Micro Focus) Quality Center and Application Lifecycle Management in that most companies tend to track ‘defects’ identified during the SDLC in a separate tool from the ‘incidents’ identified by the end users (after the build is released into a production environment). Many ALM tools include feature & functionality that help organizations build quality into their SDLC processes, which in turn results in a higher quality software build at the point of release. The problem that has not been solved efficiently is how organizations can quickly and effectively calculate DDP as it relates to the effectiveness of regression testing cycles performed over each software release into production. The artifacts (recall: defects and incidents) exist and I have led metric reporting initiatives to manually perform the DDP calculation on a day-by-day basis, but most organizations have not recognized how value stream integration will streamline DDP calculation while illuminating the relevance of this all-too-important metric for improving the quality of regression testing coverage. The lack of focus on value stream integration often leads organizations to disregard DDP as a mainstay QA Metric in their KPI portfolio.
Although the ISTQB recognizes DDP as a formal measurement that organizations can use to improve software quality, rarely have I seen this QA metric monitored on an on-going basis to improve the effectiveness of a particular testing layer. In my article entitled, 12 Key Performance Indicators for QA & Test Managers, I outlined industry best practice QA metrics that every Software Testing Manager should be tracking. DDP was not mentioned in my article because most organizations tend to track the software defects identified in the SDLC separately from the incidents identified by the customer. My article was focused on the SDLC activities leading up to the point of release, but to drive significant improvements in the quality of your test cases (to effectively trap more defects and prevent incidents) — you must bridge ADM with ITSM and not only calculate DDP in real-time but monitor it on a daily basis.
Application Delivery Management (ADM) and Information Technology Service Management (ITSM) were often seen as separate functions in an organization. As SDLC practices evolved, organizations recognized the need to eliminate silos and integrate the flow of information between both ADM and ITSM tools. In the context of DDP, the ‘incidents’ identified by the end users can feed back over into an ALM tool to be used in a real-time DDP calculation. Beyond the simplicity of synchronizing incidents from an ITSM (e.g., ServiceNow, ZenDesk) tool back over into an ADM/ALM tool (e.g., Quality Center), embracing value stream integration preserves the integrity of the linkages established between each work artifact produced.
Let me illustrate this phenomena with a simple example. Let’s say your organization recognizes the importance of end-to-end traceability and believes that every test case should cover a requirement, and that every defect should be traced back to either a test run or a requirement. Now picture a scenario where you run a regression test over a new feature build where the team identifies a total of 30 defects. Ten of those defects are Critical Severity, Ten of them are High Severity, and 10 of them are Medium Severity. Each defect uncovered occurred during the execution of either a manual or automated test, therefore traceability exists from the defect back to the test run, and back to the requirement that the test was originally designed to cover. Are you still following my logic? If not, read the last few sentences again so that you follow this next section very closely.
All 30 of the defects identified during the regression testing cycle were fixed and closed. The regression test suite was re-executed, and the software worked as designed — no defects. Since no defects were found, your team receives a green light for a production push. The calm before the storm ensues as your team works flawlessly to transport code from your sub-production to your production environment. Meanwhile, your end users anxiously await this new and exciting feature that has been the talk of the company for weeks. On Monday morning, you decide to login to your ITSM tool to see if the end users have identified any Incidents. Nothing so far. You go about your daily routine, grab lunch with a friend, and then decide to check the ITSM tool again after lunch to see if any Incidents were logged. Suddenly, you recognize 5 critical incidents! Your stomach turns because after all you’re the Testing Manager and fully responsible for the quality of the regression tests running for every new software build. Your DDP was 100% before lunch, now its quickly dropping with every incident uncovered by the end users. Even worse, your Shipping Clerk at the Central Distribution Center just logged an incident about a critical master data issue preventing the fulfillment of orders for your company’s largest customer. Your mind races: “How did this occur? Our last regression testing cycle was flawless — what went awry?” Enter root cause analysis.
You know the drill — an emergency meeting is organized between the project’s key stakeholders to investigate, analyze, and determine the root cause that resulted in the critical incidents identified in production. Luckily, you’re armed with not only a test coverage analysis report, but also a full end-to-end requirements traceability matrix (RTM). Surely these tried and true methods to Software Quality Assurance ensured adequate test coverage! No way is your team responsible for letting these ‘abnormalities’ slip through into the productive environment.
Then it dawns on you. Your end users identified a similar set of incidents for a much less impactful area of the business last month. Luckily, you dodged a bullet last month because the incidents uncovered didn’t result in business operation failure. You made a mental note last month to manually mark the set of requirements in your ALM tool as needing updated, which in turn would mean more work on the associated regression test cases tied to the requirement. In other words, the regression testing suite that covers the set of requirements related to the root cause (e.g., master data) needs to be enhanced with additional parameters, configurations, and branch logic to exercise variables that are critical to day-to-day business operations. Your “mental note” to manually flag the associated requirements was crowded out with other fire drills, meetings, and interruptions — resulting in a huge oversight on your part.
Root cause identified: lack of value stream integration between the ALM tool and the ITSM tool. If last month’s incidents were synchronized back into the ALM tool and subsequently traced (linked) back to the originating requirements that needed re-worked, the QA Team would have quickly recognized the need to enhance the associated regression testing suite (traced to the regression-relevant requirements). The lack of end-to-end value stream integration from a tooling perspective in this make-believe scenario resulted in an oversight that cost this organization millions in lost confidence, late shipments, and production overruns.
3. |
Closing the feedback loop to Fast Change Requirements. How many times have we seen organizations using Microsoft SharePoint lists to track Change Requests (CRs), separate from the tool they are using to develop test cases for Unit, System, Integration, Regression, and UAT? Disaster looms if you can’t associate the artifacts. Here’s why: |
In today’s fast paced world of software development, it should come as no surprise when I say that your requirements are ever-evolving. A requirement defined last year is likely going to evolve in some fashion or another. The evolution of that requirement may be simple – perhaps a new value on a drop down, or a subtle change in the style of the dialogue box that appears when a function is called. Or the original requirement might undergo a complete uproot and overhaul with significant code re-factoring. Either way, small or large, the requirement has evolved from its original structure. As the software requirement evolves, many different people, processes, and tools are ‘touched’ along the way. Let’s take a quick look at a simplistic flow of how a feature request turns into a change request to an originating requirement that ultimately affects the regression test suite you have created for your software application.
✓ |
Your customer submits a feature request and suggests that you add the ability to XYZ in your software. | |
✓ |
The request is consumed into either a homegrown system, or perhaps you’re using one of the popular tools to log and track feature requests. Either way, you receive a few sentences from one of your customers about: “Geez, wouldn’t it be nice if your software did this!” | |
✓ |
The feature request sits there for a few days and is then reviewed in your backlog grooming meetings and/or discussed amongst the product management team informally. | |
✓ |
It sounds like a cool feature that could put your SaaS platform into growth mode. All the product managers scratch their head universally, thinking: “Um, why didn’t we think of this?!” | |
✓ |
You reach out to the customer who submitted the feature request and ask for additional information to crystallize and clarify their genius idea. Since they enjoy being heard and involved in the evolution of your SaaS platform, they happily agree to participate in a Joint Application Design (JAD) session with your R&D team over a GoToMeeting (GTM). | |
✓ |
The requirement is refined, defined, and crystallized – it’s a breakthrough feature request that is ready for approval by the business with a funding request to hit the R&D priority list. | |
✓ |
The Business (the Investors) approve a Change Request (CR) to an existing Functional Requirement and allocate 160 hours of R&D of which 40 hours is allocated for the quality assurance and testing efforts. |
Every organization is different in their requirement intake process – but this characterizes a general intake workflow for a SaaS platform backed by investors. Now that you have the business approval for 120 hours of coding and another 40 hours of software testing for this innovative new feature – it’s time to analyze, design, build, test and deploy. It’s a small and impactful project, so time is of the essence.
Your team gets to work immediately by reviewing the original functional requirement to ensure all variables are known. Your Solution Architect pulls out the technical design and sketches that you originally pulled together nearly 3 years ago. Can you believe that JPEG images were embedded in the technical design from the whiteboarding session your team had when designing the original feature. Crazy, but very useful. You analyze the embedded JPEG images – all the boxes, diamonds, and arrows drawn on the whiteboard make you dizzy.
Meanwhile, if you’re lucky, your QA Guy or Gal was involved in the customer-facing discussions to conceptualize the impact that the proposed enhancement will have on the existing software application. At this point, you look at the work items (also known as artifacts), including the regression tests that you designed to cover this feature and you ask your QA team to investigate. After all, this feature that your team is about to enhance is a critical function of your software application. Without this feature working as designed, your customer base will not be able to execute the core function of your software – to collect money! There are four (4) regression tests and another two (2) end-to-end regression tests that trace back to this specific feature. Looks like the original design team took the time to document scripted regression test cases for this critical feature of the product. Phew, thankfully you called this out in the JPEG whiteboard image that you embedded in the technical design MS Word document.
You open Google Drive and click down through to your “Regression Tests” folder to find a barrage of Microsoft Word documents and Excel Spreadsheets with a variety of naming conventions. Some of the test cases are half-baked with old data from a QA Analyst that hasn’t worked here in about 6 months. You’re not entirely sure whether the test cases are substantial enough to truly cover all edge cases of the requirement. Did they exploratory test one of the most important features of this SaaS product? You privately think: No way did the founding team of this SaaS product exploratory test the most critical feature of the platform without properly documenting regression test cases. Then you remember the pressure they were under to deliver the minimum viable product (MVP) with speed and feel empathy.
At this moment, you secretly wish that you would have worked a few weekends to structure and create the end-to-end requirements traceability that everyone kept harping on in the early days. Better yet, you should have started using one of those popular Agile Planning tools to interlink (trace) the regression test cases back to the original requirements. Why? Because you’re not even sure if the regression tests you found adequately cover the existing feature-functionality of this core piece of functionality. Your nervous – but power forward and ask your QA team to review the existing test cases and suggest additional coverage as needed.
With only a few weeks to analyze, design, develop, test, and deploy – your QA team doesn’t bother establishing any sort of interlink (e.g., a requirements traceability matrix) between the existing regression test cases and the original requirement, nor do they bother defining the relationship between the new test cases created and the first change request written. It’s “understood” amongst the small team as interactions are valued much more than process and documentation. After all, you embrace the Agile Manifesto to the extreme.
What is wrong with this picture?
From an Agile practitioner perspective, the Agile Manifesto asserts ‘individuals and interactions over processes and tools’ plus ‘working software over comprehensive documentation.’ Why are you going to waste your time entering the Change Request into one of those popular tools, tracing it back to an original User Story or Epic, and then ensuring that the regression test cases are also linked/traced back to the Change Request? Your team is on the same wave length — you can feel it at the morning Agile standups! Wrong. An extremist outlook on anything, in my opinion, compromises the long view. In other words – a lack of balance and holistic understanding of value stream integration will inevitably lead to test coverage oversights, mishaps, and critical defects.
Fast forward 2 more years. The team you had “on the same wave length” decided to use the great experience they gained at your SaaS company and move down the road for a new experience. The core functionality of your SaaS platform needs another overhaul due to regulatory changes and another software change request is approved by the board of directors. Without value stream integration, the loop from the change request to the originating requirement over to the regression test cases is simply not readily accessible – leaving a tremendous amount of room for human error. With a balanced approach to Value Stream Integration and Agile development, your team would have the structure and traceability readily available years into the future as the system evolves. More importantly, your QA team can propose a regression test scope with confidence!
4. |
Infusing cross-platform alerting capability for Work Artifacts is central to driving Software Quality Assurance. Testing must always mirror requirements and one should always question the validity of a test case without an associated requirement to cover. Let me explain what cross-platform alerting is and how value stream integration drives a higher level of awareness and quality assurance. |
I recall writing an article in 2011 timeframe entitled A Roadmap to Streamlining User Acceptance Testing. In that article published by Software Test Professional Magazine, I chronicled my experiences as a Test Lead for a $200 million-dollar .NET software platform implementation at a State Medicaid Organization. Candidly, it was a painful experience – but it illuminated a lot of what can go wrong on a project if you’re not careful. That lessons learned article I wrote climbed to the top spot on Google for keyword searches like “UAT Best Practices” and still receives thousands of monthly views on my LinkedIn Pulse account, STP, and another vendor’s blog where it was published. Until this day, I receive private messages on LinkedIn asking me for the “Desk Aide” that I referenced in the article from UAT Testing Managers across the world. Apparently, a lot of other practitioners experience the same “pain” that I outlined in that article – leading me to believe that misery really does love company! All joking aside, if you had a chance to read that article, I talked about ‘bridging the gap between tools’ in #5:
Bridge the Gap Between Test Management Tools
Developers and QA personnel (e.g. UAT Testers) don’t always agree on the use of one test management tool over another to track defects, test plans, test cases, etc. The bottom line is that your organization will need to decide on one system of record for test management. If your QA Team prefers HP Quality Center, but the solution integrator prefers JIRA (for example) for internal task tracking, it becomes increasingly important for you to build a bridge between the two applications to maintain transparency with the system of record. Without the bridge (interface), it will quickly become an administrative nightmare. If your UAT team is going to build custom test scripts in a tool like HP Quality Center, make sure they link each script (or test cases) to its appropriate business requirement. The linkage may be a critical component to ensuring that the interfaces to other ‘system repositories’ capture everything in the daily batch cycle.
Seven years ago, I didn’t realize that I was writing about the lack of Value Stream Integration in the Roadmap to Streamlining User Acceptance Testing. All that I knew is that I experienced tremendous pain from the lack of integration between the tools chosen by a State Agency and a Solution Integrator (SI) to lead the implementation. My pain on that project stemmed from the lack of upstream traceability to the originating requirements when defects were logged in Quality Center. Although the UAT testers assigned to the project were logging defects against the test execution runs, zero traceability existed back up to the requirement-level because the SI was not using QC for requirements management. I believe they were documenting requirements in SharePoint, Clarity or another tool at the time. Not being able to “swim upstream” put me at a disadvantage when it came to risk-based quality assurance. Why? Because the project was a multi-year implementation where the SI performed unit, system, and integration testing. My focus was on Interface and User Acceptance Testing. The lack of upstream traceability didn’t allow me to analyze the historical context of high-risk requirements to bolster end-to-end interface testing. It was a game of either rolling the dice or gathering subject matter expertise input (qualitative).
During my weekly status update meetings with the Executive Project Management Team, I was often put on the spot to answer questions about preparedness for future testing cycles based on historical data. I recall a few times trying to explain in a meeting to the Executive PMs why the lack of upstream traceability was making it difficult for me to identify what requirements generated the bulk of defect activity overtime.
The lack of visibility was making it even harder to properly plan the next testing layer. Unfortunately, many Project Managers consider this an “excuse” and their eyes would glaze over when I talked about the importance of artifacts interrelating and why its important to embrace the long-view with software evolution. Candidly, I felt as if I was in the twilight zone at times because most people are focused on the “here and now” without regard to structuring a solid foundation of artifact interconnectedness to protect the quality of the software build for many years into the future. As a QA practitioner, you know the importance of building a solid foundation in that you achieve end-to-end traceability amongst all artifacts in your SDLC – whether it’s a Waterfall-centric project, an Iterative/Hybrid project, or a Scrum/Agile project – traceability is a must-have requirement.
Ensuring forwards and backwards traceability enables cross-platform alerting. When a defect is logged in your test management tool and synchronized back to another tool – platforms like Tasktop Integration Hub can preserve the integrity of the artifact relationships up to the requirement-level. The preservation of the artifact relationship (aka, the traceability) can “alert” the owners of the associated requirements that a hotbed of defect activity is occurring. What’s more is that many tools will alert (by email) the owners of the test cases traced to the requirements when a child requirement is traced back up to the originating requirement. This is particularly useful when Change Requests (CRs) are created and traced back to an original requirement. As requirements evolve, the associated test cases must either shrink or expand to accommodate test coverage needs.
5. |
Shifting Left – involving QA very early in the SDLC – eliminate the “throw it over the fence” mentality and root out defects very early. Shifting left is all the buzz in the industry when it comes to improving software quality. How do we implement this concept though? |
Who would have imagined that Beyoncé Knowles, one of the world’s most recognized female recording artists, could speak directly to software quality professionals with her #1 hit ‘Irreplaceable’ (hint: to the left, to the left!). I recall penning an article in 2015 defining what ‘shifting left’ truly meant to software quality professionals. In that article, I talked about how everyone keeps talking about ‘shifting left’ to lower costs, reduce defects, and improve software quality. The problem was that people simply assumed that everyone understood the fundamental tactics of accomplishing just that – shifting left. Vendors abound embraced this new term and built their marketing strategies around how their product can help companies shift left – but there is more to the story of shifting left than tools. The tools are a key ingredient to shifting left, but with a few other ingredients your cake just got that much sweeter.
To put it simply, shifting left is all about testing earlier, testing often, and identifying and fixing defects when its less costly to do so. It’s also all about involving your QA team in the earliest aspects of enhancements or new product build outs. Tools like Micro Focus LeanFT are designed to expand unit testing coverage at the earliest phase of your delivery lifecycle, whereas more traditional tactics like ‘static testing’ requirements (an ambiguity check) are still very useful methods to infuse quality early in the delivery lifecycle. Value stream integration will ensure that the activities performed upstream (to the left) are visible to the subsequent delivery activities performed downstream (to the right). Why does having upstream and downstream visibility matter?
I’ve never heard a CIO tell his team to ‘shift right’ and identify bugs at the last possible moment before the go-live date. As we know, the cost to fix a defect increases with each testing layer (e.g., unit, system, integration, UAT, regression) and sky rockets if the bug slips through to production. Having the ability to swim upstream and downstream along your value stream gives you the following capabilities:
- View the defects identified at each phase of the SDLC for a requirement – from design, to build, to build, to test, and production. As mentioned in #2, seeing the incidents raised by our end users helps us calculate the DDP to understand how effective we are at ‘trapping’ bugs with a regression testing cycle.
- By starting downstream (at the defect) and swimming back upstream, you can go artifact-by-artifact to closely analyze what ‘testing layer’ failed to first identify the bug in the first place. For example, why was this defect uncovered by the business during User Acceptance Testing instead of further upstream? Was it the result of inadequate unit testing, the result of miscommunication between teams, or perhaps the design of your system tests didn’t exercise a branch of logic needed to trap the bug?
These types of questions help you to identify the root cause of an issue. Identifying the root cause, often a function of Quality Assurance, is markedly more efficient when an organization embraces value stream integration.
6. |
Reducing the Ping Pong Effect – Developer and Tester Alignment can be tightened across tools with a focus on Value Stream Integration. Bug fix time improves, and test coverage improves as QA Analysts aren’t explaining each step they took in the software under test to uncover a bug. |
Ping ponging is the back & forth that we often seen between QA and Development. Most vendors have introduced either add-ons or specialized tools like Micro Focus Sprinter to reduce this phenomena. The specialized manual testing tools help to: accelerating testing, capture screen shots automatically, while allowing the developer to re-create defects by following the exact steps taken by the QA engineer to produce an error in the first place. In short, these tools automatically attach the testing evidence leading up to the creation of the bug (e.g., evidence = steps taken, data used, screen shots, and the actual error created).
How many times have you witnessed comments or emails flying back and forth between QA and Development regarding an error uncovered during testing? The development team cannot re-produce the error because they don’t know the exact test steps and data inputs used to create it in the first place. As we know, not all testing is scripted – QA engineers are expected to keep up with the velocity of Agile teams and are often exploratory testing applications to meet aggressive delivery timetables. Specialized tools like Micro Focus Sprinter, or the built-in manual test feature within Micro Focus ALM Octane are designed to reduce the ping ponging between QA and Development. Microsoft TFS has a Chrome Add-in available for this same purpose, whereas tools like Panaya have a built-in manual tester feature. All these add-ons, built-in features, and tools serve roughly the same purpose: to accelerate manual testing while capturing every single step of the ‘action’ that occurs while testing. Several of the tools, such as Panaya, also capture the data inputs taken by the end user. This is especially helpful for User Acceptance Testing (UAT) phases of a large ERP project. The next User Acceptance Tester “next in line” can easily see and use the data set from the previous step to continue their task (as an input) in the next step within the software under test.
Ping pong is a great sport if you’re Forrest Gump, but pure waste for Software Development projects. The vendors I’ve mentioned herein have all done a fantastic job of aligning the Tester and Developer experience within their respective platform (e.g., ALM Octane, Microsoft TFS, Panaya), but what happens when an organization is using another best-of-breed tool like SAP’s SolMan ServiceDesk to track and resolve defects? Even if your SAP User Acceptance Testing is running like a brand-new BMW 5 Series with Panaya, the defects are getting logged in Panaya (not SAP SolMan ServiceDesk). Why? Because the platform is designed to closely interlink the QA and Bug-Fixing experience, so it’s natural for the UAT tester to log their bug in that platform. Same principle applies for other tools such as Microsoft TFS and Micro Focus Octane. The problem is that your ABAP’ers are using SAP’s SolMan ServiceDesk to field, triage, and resolve defects – they always have, and always will. The last thing your ABAPers want to do is login to yet another tool to review the defects assigned to them. They desire to work within their tools of comfort – not bounce between multiple tools.
If you’re organization is like most and using multiple tools across disparate development and QA teams, and you want to avoid a Forrest Gump scenario, then you should be asking yourself whether Value Stream Integration is at the top of your CIO’s agenda. Let’s face it, different departments are led by different people – which have different personalities, different budgets, and tool biases. Forcing everyone onto the same unified platform from a tooling perspective only works with Enterprise Resource Planning software (IMHO). Even so, many large companies run instances of both SAP or Oracle because of M&A activity and choose to keep it that way out of preference!
Embracing Value Stream Integration will ensure that your ABAP’ers and Bug-Fix Team can continue to work out of their tool-of-choice, whether that be SAP’s SolMan ServiceDesk, or perhaps even JIRA – while your Business Analysts and User Acceptance Testers embrace software that Panaya, Microsoft TFS, and Micro Focus Octane have to offer for everything else. It’s truly a win-win in that the associated screen captures, attachments, and comments associated with the defect logged in one tool flow easily into the other software being used by your Bug-Fix team. This enables them to quickly update the comments, change the status, and follow the sequence of activities that occurred without wasting time playing ping pong like Forrest Gump with your QA team.
7. |
Building a Global Testing Center of Excellence (TCoE) does not require a unified tool as a single source of record for all working artifacts (releases, requirements, tests, defects, reports). One size does not fit all. Establishing a model of communication within your TCoE for all tributaries to converge into one river produces better results than tool consolidation. You can thrive with a multi-tool strategy across your lines of businesses. Let me explain why and how. |
I’m going to quote yet another movie to illustrate my point. Read this quote from Norman Maclean from ‘A River Runs Through It’:
“Eventually, all things merge into one, and a river runs through it. The river was cut by the world’s great flood and runs over rocks from the basement of time. On some of the rocks are timeless raindrops. Under the rocks are the words, and some of the words are theirs. I am haunted by waters.”
― Norman Maclean, A River Runs Through It
Focus your attention on his opening sentence: Eventually, all things merge into one, and a river runs through it. Your river might be your release train, or perhaps the monthly service pack that you’ve committed to your internal business stakeholders. Either way, the river is raging and there is little to stop its momentum. It’s a fun ride if you’re with the right tour guide, but if you don’t take proper precautions – you can easily get swept away in the current or get caught in the under tow.
One thing you might notice about rivers, whether it be the Nile River in Africa, or the Mississippi River in the United States is that they both have many tributaries. In the United States, the Mighty Mississippi drains about forty-one percent of the country’s rivers. Looking at the map below, you will see that the Arkansas river, the Illinois River, the Missouri River, the Ohio River, and the Red River all “merge into one” (the Mississippi) and eventually empty out into the Gulf of Mexico.
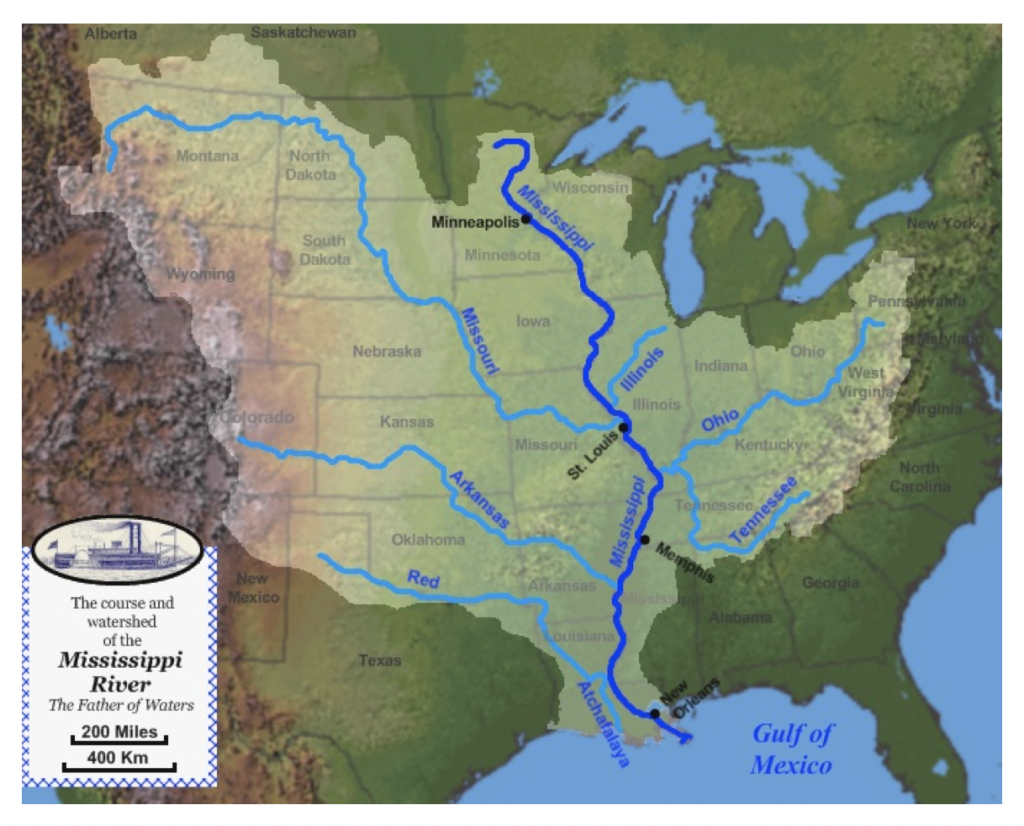
This powerful analogy about America’s river system underscores the fact that all things merge into one, and a river runs through it. How I see the world of Software Delivery is that best-of-breed DevOps and QA tools tend to flow into a keystone platform were the record of metrics and reporting exist.
We can’t improve what we can’t measure – therefore, it is critical to build the right Key Performance Indicators and QA Reporting Strategy within your Testing Center of Excellence. One problem you might face is the QA metrics you want to report out are generated by disparate tools across multiple lines of business. You have a few approach options as a TCoE Leader when faced with this problem:
- Swiss Army Knife and Duct Tape Approach
- Tool Consolidation & Unification Approach
- Value Stream Integration Approach
Option A is highly error prone and manually intensive, whereas Option B seems to be the most logical approach of standardization, unification, and consolidation across an enterprise. Option C, on the other hand, helps organizations to embrace the diversification of toolsets.
With Tasktop Integration Hub, organizations can start small by adopting a hybrid approach to improving the accuracy of their QA metrics. Establishing a model of communication within your TCoE for all tributaries to converge into one river produces better results than tool consolidation.
About the Author
Matt Angerer – Sr. Solution Architect
Mr. Angerer is a Sr. Solution Architect for Tasktop Technologies, the industry leader in value stream integration. Prior to Tasktop, Matt served in a variety of QA and Testing Leadership roles. He has over 15 years of experience in enterprise, mission-critical system implementations, and support for global multinational companies. His editorial contributions can be read on LinkedIn. You can reach Matt directly at matt.angerer@tasktop.com.
Trackbacks/Pingbacks