
It’s 1985. The charity single “We are the World” climbs the charts, “New Coke” hits supermarket shelves, Back to the Future is the highest grossing film, and the following ad runs in the Seattle Times (Figure 1):
“As a Software Tester you will design execute and document tests of application software. You will generate test scripts and automatic test packages.”
Does this sound like the entirety of your job? Then I encourage you to come Back to the Future. Test and automation are, and likely always will be, an important tool in our quality arsenal, but you should also be asking if there have been any advancements in software testing over the past 27 years that you could possibly be leveraging also, especially if you are responsible for software services.
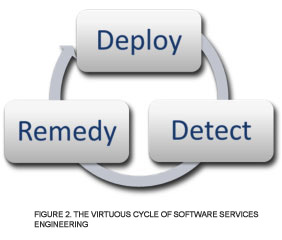
With services we control the deployment and we can monitor the systems and usage. This gives testers unprecedented power to find issues and quickly have them remedied while the product is being used in production. This virtuous cycle (Figure 2) then enables engineers to assess the impact of the deployed fix, and then make any additional changes that are necessary.
Let’s focus on that Detect block. If we have engineered our systems right, there is a constant and rich flow of telemetry data emitting from our product. How efficient we are at leveraging that data pipeline determines how successful we will be at exploiting this data to improve product quality.
 What is in this data and what does it look like? Broadly it can be divided into three categories organized as a stack or hierarchy:
What is in this data and what does it look like? Broadly it can be divided into three categories organized as a stack or hierarchy:
- System metrics comprise the base level of operations. Knowing measures like CPU consumption, disk I/O, and network load enable testers to understand the how well the environment (whether it be physical servers or the cloud) is hosting our services. System metrics are often thought of as the domain of Operations, but Testers also need to utilize this important signal.
- Application Metrics tell us how well the services themselves are functioning. The timing (latency) of API calls is in itself interesting, but track these over time and that spike on the graph will quickly reveal to the tester that a possible bug has emerged or that usage load has exceeded the system’s capacity. But don’t limit this to just the API, measure the entire workflow for a user scenario to get a rich assessment of what your users are experiencing.
- Business Metrics tell us what users are doing, and what better way to assess system quality than by understanding how users engage with your product? Revenue is often the ultimate of the business metrics, but click-through rates and page views give us other ways to assess user engagement also. These metrics are often thought of as the domain of Program or Product managers, but testers must be aware that a drop in business metrics may signal a serious bug.
Some examples of how this data has been used for quality:
- At Etsy they use 40,000 real time metrics to shore up their assertion to “Graph or it didn’t happen”
They describe using metrics from all three layers in their quality assessment including:- System: Load, Memory, and Network
- Application: Image processing times, Image creation times, and Image network storage times
- Business: Checkouts, including the number of these that error out.
- At Facebook “developers instrument everything” . They use the open source product Ganglia to collect system metrics, and their own Operational Data Store to produce and trend application metrics such as total queries and memcache performance.
- Amazon.com makes it easy for service developers to instrument every API call using centralized tools and dashboards. Tp99.9 is the king of application metrics at Amazon – for a given API a tp99.9 of X msec means 99.9% of the calls completed in under X msec. When tp99.9 starts to creep up pagers go off and engineers are tasked with analysis and remedy of the problem.
- For Microsoft’s Bing, business metrics are looped back into the system to improve quality and user experience. “what [users are] clicking on, when they search for something, what do they get to next, what do they seem to be happy with, did they refine those search queries and do other types of searches, can we learn based on that behavior?”
- Using intelligent instrumentation Microsoft Hotmail (now Outlook.com) uses anonymous data to see how long page loads (an application metric) took for millions of users. Using this data they were able to target and improve performance bottlenecks
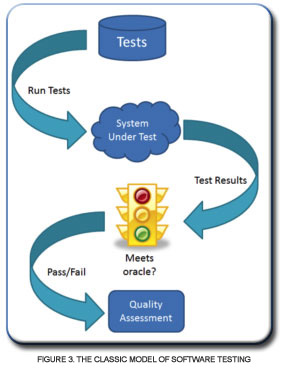
In conclusion, the 1985 model of software testing looks like Figure 3
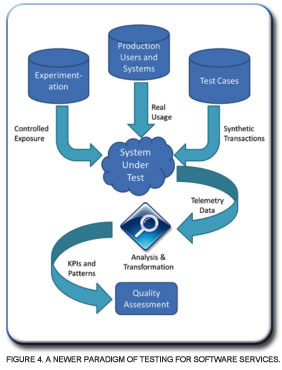
The challenge for the 2012 tester is can they shift that model to also include real data from their production systems and make it look more like Figure 4? If not then let’s put on a 45 of “We are the World”, crack open a couple of New Cokes, and have a chat.
http://www.slideshare.net/noahsussman/fast-and-good-alternate-approaches-to-quality-at-etsy-stpcon-fall-2011 slides 34-37
http://www.youtube.com/watch?v=T-Xr_PJdNmQ
http://37signals.com/svn/posts/1836-the-problem-with-averages [in comments section]
http://www.seomoz.org/blog/director-of-bing-discusses-holistic-search-and-clickstream-data-whiteboard-friday
http://www.setheliot.com/blog/a-to-z-testing-in-production-tip-methodologies-techniques-and-examples-at-stpcon-2012/ slide 29
About the Author
Seth Eliot Senior Knowledge Engineer in Test, Microsoft –
Seth focuses on driving best practices for services and cloud development and testing across the company. He previously was Senior Test Manager, most recently for the team solving exabyte storage and data processing challenges for Bing, and before that enabling developers to innovate by testing new ideas quickly with users “in production” with the Microsoft Experimentation Platform Testing in Production (TiP). TiP, software processes, cloud computing, and other topics are ruminated upon at Seth’s blog at http://bit.ly/seth_qa and on Twitter (@setheliot). Prior to Microsoft, Seth applied his experience at delivering high quality software services at Amazon.com where he led the Digital QA team to release Amazon MP3 download, Amazon Instant Video Streaming, and Kindle Services.