When It Comes To Security Auditing, One Size Does Not Fit All
One key problem with security code audits is that they tend to cause more problems than they solve. “One size fits all” audit scans tend to overwhelm developers, ultimately leaving the team with a long list of known problems, but little actual improvement. In fact, when an audit tool is used near the end of an application development cycle and it produces a significant number of potential issues, a project manager is put in the uncomfortable position of having to decide whether to delay the project and to remediate the code, or send it out into the market as-is.
Trying to inject security into an application through testing is a fool’s errand. The number of paths through an application is nearly infinite, and you can’t guarantee that all those paths are free of vulnerabilities. It’s simply not feasible to identify and test each and every path for vulnerabilities. Moreover, errors would be difficult to fix considering that the effort, cost, and time required to fix each bug increases exponentially as the development process progresses. Most importantly, the bug-finding approach to security fails to address the root cause of the problem. Security, like quality, must be built into the application.
Building security into an application involves designing and implementing the application according to a policy for reducing the risk of security attacks, then verifying that the policy is implemented and operating correctly. In other words, security requirements should be defined, implemented, and verified just like other requirements.
For example, establishing a policy to apply user input validation immediately after the input values are received guarantees that all inputs are cleaned before they are passed down through the infinite paths of the code and allowed to wreak havoc (see Figure 1, below). If this requirement is defined in the security policy then verified to be implemented in the code, the team does not need to spend countless resources finding every bug and testing every possible user input.
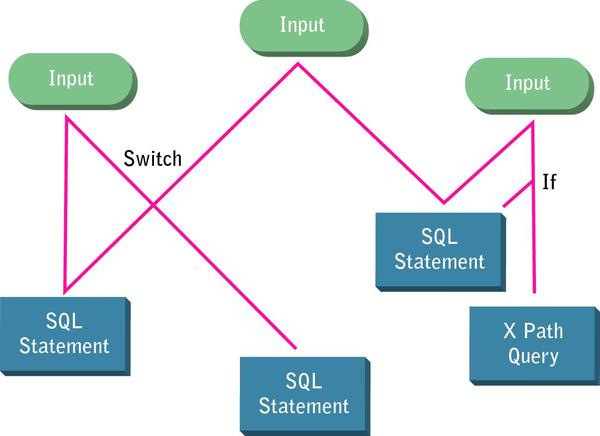
One of the best strategies for building security into the application is to define how code needs to be written to protect it from attacks, then use static analysis to verify that the policy is implemented in the code. This article provides an overview of how this can be accomplished.
Establishing A Security Policy
Writing code without heed for securitythen later trying to identify and remove all of the application’s security vulnerabilities is not only resource-intensive, it’s also largely ineffective. To have any chance of exposing all of the security vulnerabilities that may be nested throughout the application, you would need to identify every single path through the application, and then rigorously test each and every one. A policy-based approach helps alleviate that problem.
Security policies are espoused by security experts, such as Open Web Application Security Project (OWASP), and are mandated for compliance with many regulations, such as Sarbanes-Oxley, that require organizations to demonstrate they have taken “due diligence” in safeguarding application security and information privacy. Yet, although the term is mentioned frequently, it is not often defined.
A security policy is a specification document that defines how code needs to be written to protect it from attacks. Security policies typically include custom security requirements, privacy requirements, security coding best practices, security application design rules, and security testing benchmarks.
What do you do if your team does not already have well-defined security policy? If the organization has designated security experts, they should be writing these requirements. If not, security consultants could be brought in to help develop appropriate requirements for the specific application under development. Obviously, this would require considerable interaction with the internal team members most familiar with the application.
The security policy should describe what types of resources require privileged access, what kind of actions should be logged, what kind of inputs should be validated, and other security concerns specific to the application. To be sure key requirements are not overlooked, I recommend listing all the important assets that a given application interacts with, then prioritizing them based on the importance of protecting each asset.
Applying the Security Policy
Having an effective security policy defined on paper will not translate to a secure application unless the security policy is followed during development. Static analysis can be used to automatically verify whether most security policy requirements are actually implemented in the code and identify code that requires rework. Verifying the remaining security policy requirements might require unit testing, component testing, peer code review or other techniques.
Using static analysis to automatically verify the code’s compliance to application-specific security policy requirements (for instance, for authentication, authorization, logging, and input validation) requires expressing those requirements as custom static analysis rules, then configuring the tool to check those custom rules. Often, developing such custom rules is simply a matter of tailoring the static analysis tool’s available security policy rule templates to suit your own policy. For instance, custom SOA security policy rules can be created from templates such as:
- Do not import WSDLs outside a certain domain
- Do not import schemas outside a certain domain
Custom Java security policy rules can be created from templates such as:
- Ensure all sensitive method invocations are logged
- Allow only certain providers to be specified for the ”Security.add Provider()” method
- Keep all access control methods centralized to enforce consistency
Static analysis can also be used to check whether code complies with industry-standard security best practices developed for the applicable language and technologies. Many available static analysis tools can check compliance to such standards “out of the box,” and with no special configuration.
If you are developing in Java, you would want to perform static analysis to check industry-standard Java security rules such as:
- Validate an ‘HttpServlet Request’ object when extracting data from it
- Use JAAS in a single, centralized authentication mechanism
- Do not cause deadlocks by calling a synchronized method from a synchronized method
- Use only strong cryptographic algorithms
- Session tokens should expire
- Do not pass mutable objects to ‘DataOutputStream’ in the ‘writeObject()’ method
- Do not set custom security managers outside of ‘main’ method
For SOA, you would want to check industry-standard rules such as:
- Avoid unbounded schema sequence types
- Avoid xsd:any, xsd:anyType and xsd:anySimpleType
- Avoid xsd:list types
- Avoid complex types with mixed content
- Restrict xsd simple types
- Use SSL (HTTPS) in WSDL service ports
- Avoid large messages
- Use nonce and timestamp values in UsernameToken headers
To illustrate how following such industry-standard rules can prevent security vulnerabilities, consider the rule “Validate an ‘HttpServletRequest’ object when extracting data from it.” Following this rule is important because Http ServletRequest objects contain user-modifiable data that, if left unvalidated and passed to sensitive methods, could allow serious security attacks such as SQL injection and cross-site scripting. Because it allows unvalidated user data to be passed on to sensitive methods, static analysis would report a violation of this rule for the following code:
String name = req.getParameter(“name”);
To comply with this rule, the code would need to be modified as follows:
try {
String name = ISOValidator.validate(req.getParameter(“name”));
} catch (ISOValidationException e) {
ISOStandardLogger.log(e);
}
XML is no safe haven either. For SOA applications, applying industry-standard static analysis rules can expose common security vulnerabilities that manifest themselves in XML. For example, static analysis could be used to parse the document type definitions (DTDs) that define XML files and check for recursive entity declarations that, when parsed, can quickly explode exponentially to a large number of XML elements. If such “XML bombs” are left undetected, they can consume the XML parser and constitute a denial of service attack. For instance, static analysis could be used to identify the following DTD that, when processed, explodes to a series of 2100 “Bang!” elements and will cause a denial of service:
<?xml version=”1.0” ?>
<!DOCTYPE foobar [
<!ENTITY x0 “Bang!”>
<!ENTITY x1 “&x0;&x0;”>
<!ENTITY x2 “&x1;&x1;”>
...
<!ENTITY x99 “&x98;&x98;”>
<!ENTITY x100 “&x99;&x99;”>
]>
Go with the Flow?
Data flow analysis is often hailed as a panacea for detecting security vulnerabilities. It is certainly valuable for quickly exposing vulnerabilities in large code bases without requiring you to ever write a test case or even run the application (see Figure 2, below).
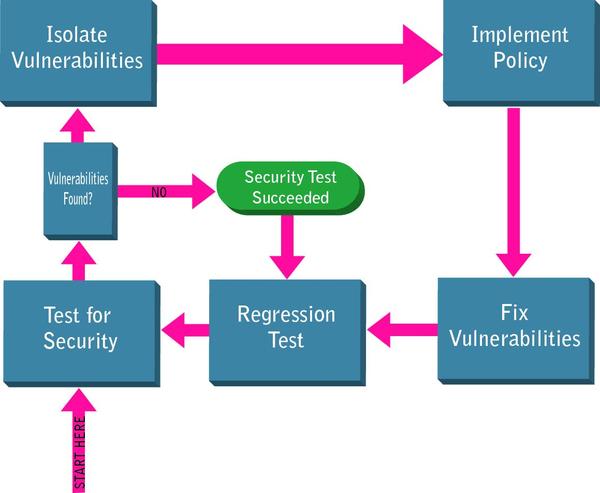
However, there are some notable shortcomings:
- A complex application has a virtually infinite number of paths, but data flow analysis can traverse only a finite number of paths using a finite set of data. As a result, it finds only a finite number of vulnerabilities.
- It identifies symptoms (where the vulnerability manifests itself) rather than root causes (the code that creates the vulnerability).
Rules-based static analysis exposes root causes rather than symptoms, and can reliably target every single instance of that root cause. If you use flow analysis, it will probably find you a few instances of SQL injection vulnerabilities, but it cannot find them all. However, if you enforce an input validation rule through rules-based static analysis—finding and fixing every instance where inputs are not properly validated—you can guarantee that SQL injection vulnerabilities will not occur.
I recommend using rule-based static analysis to prevent vulnerabilities and then employing flow analysis to verify that you implemented the appropriate preventative measures and that these measures are being applied properly. No problems should be identified at this point. Issues found at this phase usually indicate process problems that should be addressed immediately. If flow analysis does find a problem, identify its root cause, then enable or create a rule that flags the root cause. By integrating this rule into your regular enforcement process, you expose other instances of the same problem and can prevent it from re-entering the code base in the future.
Policy Implementation Workflow
As new vulnerabilities are found, isolate them and find the root cause for the issue. Once the root cause is identified, a policy is implemented around it. A fix for the vulnerability is determined, and then your static analysis tool is configured to check whether code is written according to the new rule. This checking is then added to your regularly-scheduled static analysis tests so that moving forward, you know that the vulnerability remains fixed. The policy is then applied across the application and organization— ensuring that every instance of that vulnerability is fixed.
Penetration Testing
Once you’re confident that the security policy is implemented in the code, a smoke test can help you verify that the security mechanisms operate correctly. This is done through penetration testing, which involves manually or automatically trying to mimic an attacker’s actions and checking if any tested scenarios result in security breaches. When penetration testing is performed in this manner, it can provide reasonable assurance of the application’s security after it has verified just a few paths through each security-related function.
If the security policy was enforced using static analysis, the penetration testing should reveal two things:
1. Problems are related to security policy requirements that cannot be enforced through static analysis (for instance, requirements involving Perl): If problems are identified, either the security policy must be refined or the code is not functioning correctly and needs to be corrected. In the latter case, locating the source of the problem will be simplified if the code’s security operations are centralized (as required by the recommended security policy).
2. Requirements are missing: For example, consider a Web application that requires users to register. The registration form takes in a variety of fields, one of which is the -mail address. If the e-mail field is known to take any input, the application is missing a requirement to verify that a valid e-mail address is input into the field.
Moreover, to ensure that code remains secure as the application evolves, all security-related tests (including penetration tests, static analysis tests, and other requirements tests) should be added to a regression test suite, and this test suite should be run on a regularly-schedule basis (preferably nightly). Tests are then performed consistently, without disrupting the existing development process. If no problems are identified, no team intervention is required. If tests find that code modifications reintroduce previously-corrected security vulnerabilities or introduce new ones, the team is alerted immediately. This automated testing ensures that applications remain secure over time and also provides documented proof that the application security policy has been enforced.
Don’t get stuck with Sophie’s Choice. To avoid the dilemma of having to choose between delaying a project to fix errors and deploying a product with known vulnerabilities, incorporate security from the start—at the requirements phase.
About the Author
Matt Love MATT LOVE is a software development manager at test tools maker Parasoft. Matt has been a Java developer since 1997. He holds a bachelor’s degree in computer engineering from the University of California at San Diego.